The Data Warehouse Lives On, 2022
New Memes, Old Themes
 April 2022
April 2022
Sponsored by Cloudera.
Understanding the complementary needs for and functions of data warehouses and lakes has long been vital to get the maximum value from both. Now, you also need to see where data fabric, data mesh, and data lakehouse fit.
Weaving Architectural Patterns – Data Fabric, Lakehouse, and Mesh
 December 2021
December 2021
Originally published on the Data Virtualization blog by Denodo
This omnibus collection of three blog posts explores the drivers and high level considerations for three architectural patterns that have become increasingly popular in the past year: Data Fabric, Data Lakehouse, and Data Mesh.
The Importance of a Semantic Layer for AI & BI
 November 2021
November 2021

Sponsored by AtScale
This paper explains the importance of a semantic layer, provides key lessons for successful implementations, and outlines a relatable business scenario at a fictional company called ‘BIG Supplies’.
As data volumes grow, and as information is put to an increasing number and variety of uses, defining and maintaining a record of its diverse contexts and meanings is vital.
Data catalogs have already become common sight. The semantic layer is the next frontier in placing information with active context and meaning at the fingertips of businesspeople and automating the delivery of well-managed and performant data by IT.
Rethinking Hadoop for Modern Analytics
 January 2020
January 2020

Sponsored by Teradata
Since its initial rise in 2008, Hadoop and its yellow elephant logo have become ubiquitous in the data world and are largely synonymous with the concept and implementation of big data. Both terms—Hadoop and big data—have been so used and abused in marketing by vendors and consultants alike that their real meanings have been confused and obscured.
In the past year or two, Hadoop has fallen somewhat out of favor, experiencing a set of midlife crises: of identity, confidence, deployment, cloudiness, and data governance. This series of five ThoughtPoints, published from October 2019 to January 2020, explores Hadoop’s strengths and weaknesses, and what we should do about them as we enter a new decade when analytics has become a central aspect of digital transformation.
We conclude that Hadoop is not yet dead, but that in significant aspects of its current use, enterprises would be well advised to revisit relational technology as a foundation for improved data and systems management, and as a single access point for analytics distributed among multiple technologies and across a hybrid on-premises and cloud delivery environment. Teradata VantageTM with Advanced SQL is offered as a sound foundation for such an approach.
Download omnibus 5-article pdf.
CortexDB Reinvents the Database – Full ThoughtPoint Series

August 2019
Sponsored by CortexAG
CortexDB is the first example of a new class of information management tool that allows data and context to be managed with both independence and integration, a feature that is central to reuse of information for different business purposes.
Read all five ThoughtPoints in this series in this formatted pdf.
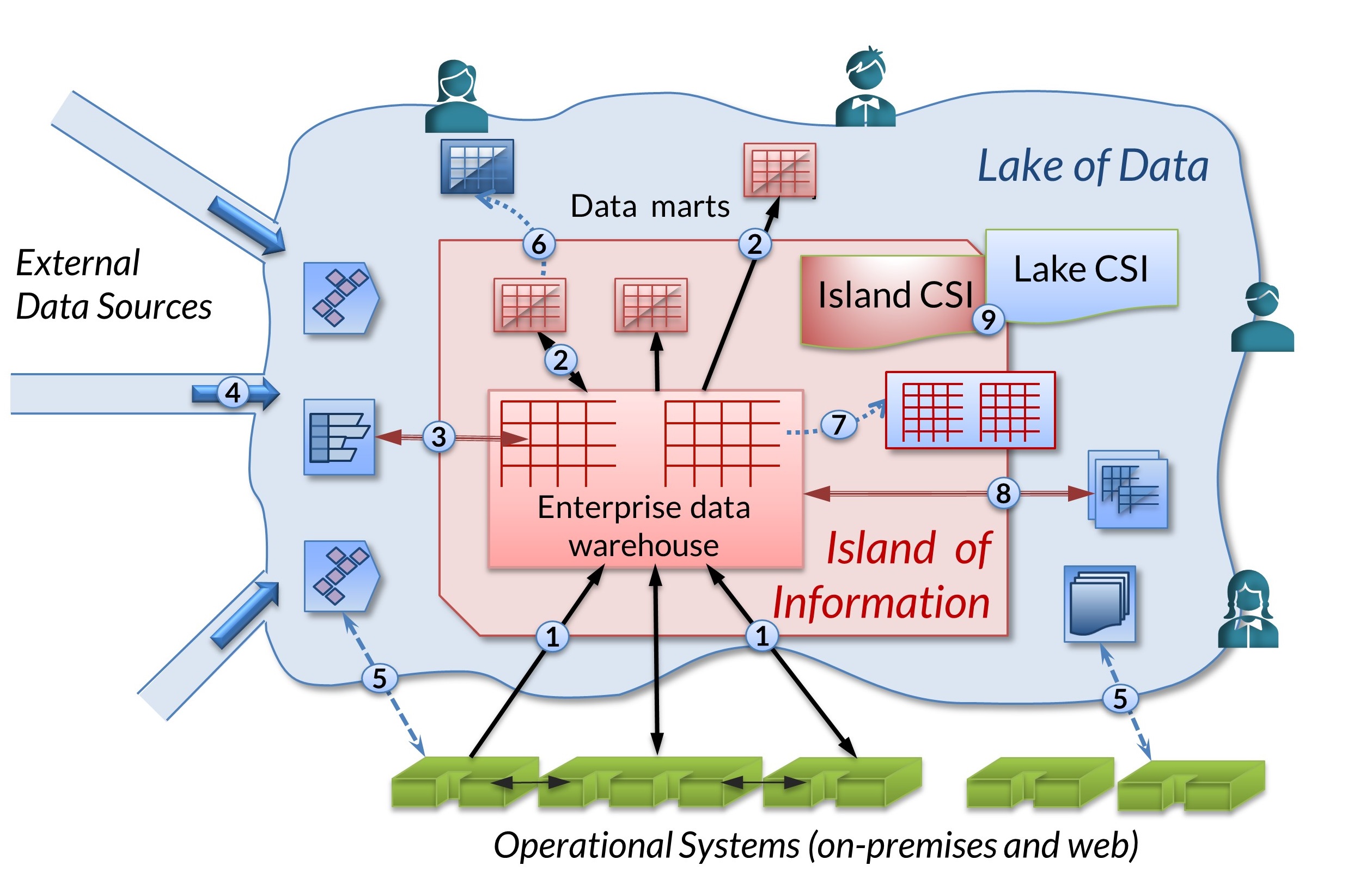
The Data Warehouse Lives On
An Information Island within a Data Lake
 July 2019
July 2019

Sponsored by Cloudera.
Understanding the complementary and parallel needs for and functions of data warehouses and lakes is vital if you want to get the maximum value from both investments.